
Simulating the Makerfield by-election with LLMs
Sending 42,000 LLM voters off to the polling booths



Today the people of Makerfield, Greater Manchester, voted for their new MP. If Andy Burnham, the Mayor of Greater Manchester, wins for Labour, he has a route to challenge Sir Kier Starmer for leadership of the party, and the position of Prime Minister. Facing him are 13 candidates, including Robert Kenyon on behalf of Reform UK, who are riding high in national polls and big gains in the May 2026 English local elections.
So we thought (at lunchtime today) it would be interesting to see if LLMs can offer any insight as to the result. Makerfield has an electorate of around 77,000 people, and we assume a turnout of 55% (considerably higher than the usual 20-40%, given the stakes). We then asked four different LLMs to pretend to be 42,265 different voters. Each time, we told them who they were: their age, gender, ethnicity, and rough household deprivation score, matching the demographics of Makerfield as per the Office for National Statistics.
We armed each virtual voter with a one-page context sheet (what this election is for, why it is attracting lots of interest, and a summary of the national polling picture and recent local election results), and a list of the 14 candidates (in a random order each time), and asked them to vote.
The result
The GPT 5.4-mini voters elected Andy Burnham, closest to the polls. All the other models – DeepSeek v4-flash, Grok 4.3, and Gemini 3.1-flash-lite – elected Robert Kenyon. For Grok and Gemini, Sarah Wakefield from the Green Party pulled into second ahead of Burnham.
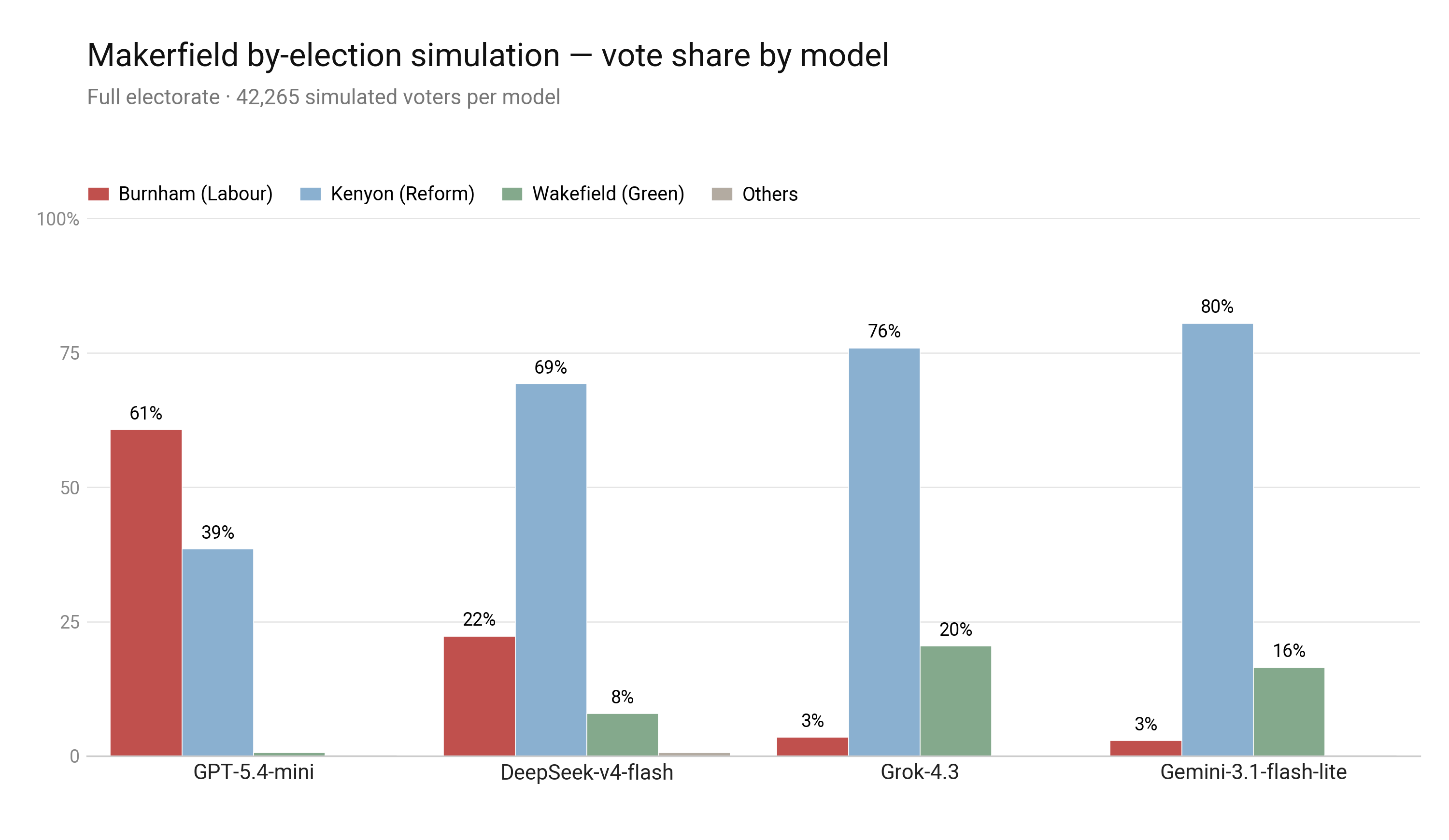
Under-35s typically vote Green (Grok/Gemini) or Labour (GPT), while 50+ goes strongly to Reform. The gender gap is consistent too (men more Reform, women more Green/Labour).
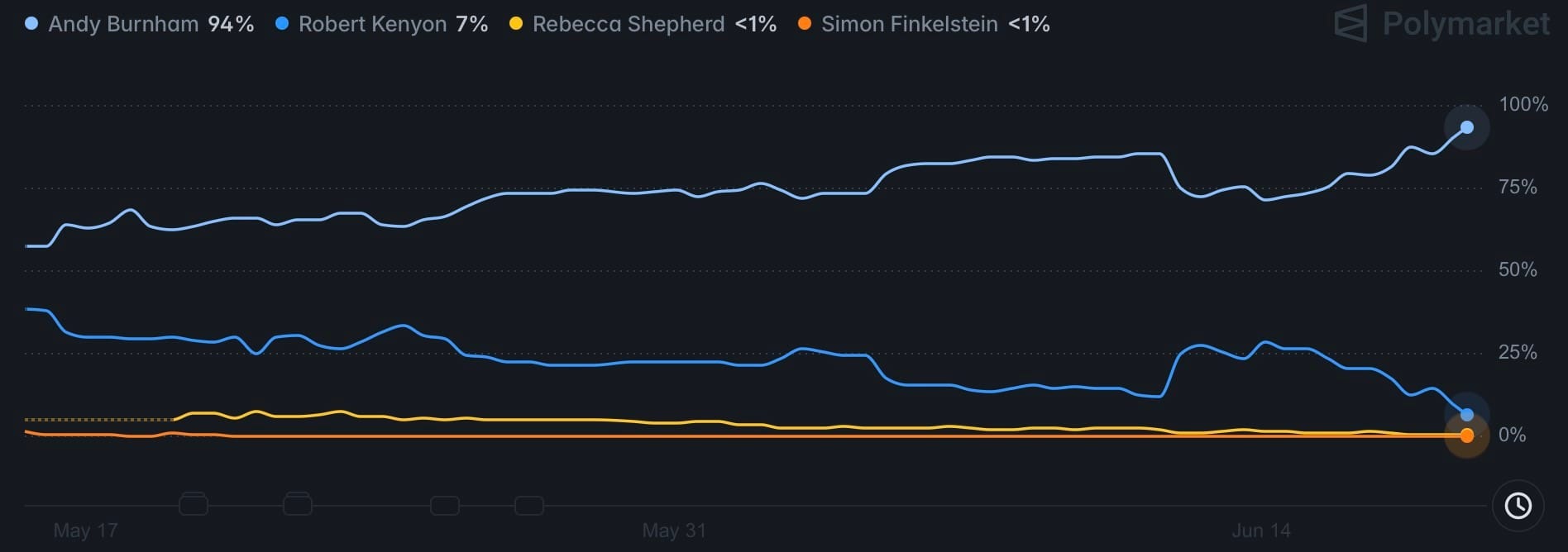
For context, Polymarket (a cryptocurrency-based prediction market) put the odds of Burnham at 94% at 2pm today, up from 72% on Sunday; Robert Kenyon was 7% at the same time (28% on Sunday).
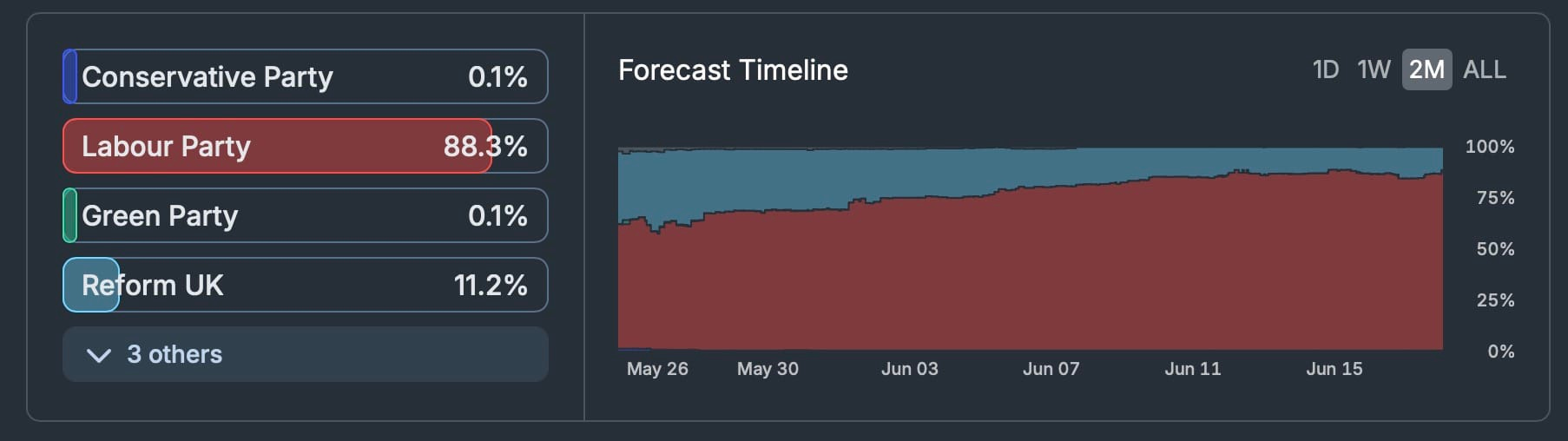
The Metaculus market (a non-financial platform favoured by forecasters) closed yesterday with Labour on 88.3% and Reform UK on 11.2%.
How did the LLMs (and the prediction markets) compare to the people of Makerfield? At the time of writing, we don’t know. We’re deliberately posting this after the polls close, and before the result is announced.
Why this is (potentially) useful
There are two reasons for doing work like this. The first is to evaluate whether LLMs can accurately simulate a persona, and could be useful for policy design, or supporting focus groups and rapid polling. Second, we can investigate LLMs themselves, and any biases that reveal themselves at scale (in the above example, we are querying each LLM over 42,000 times, and each query is an independent interaction). Is the model representing the most likely outcome only (perhaps shaped by its training data), taking a deliberately contrarian stance (perhaps shaped by post-training or system instructions), or predicting an outcome from ground up, leaning on (or skewed by) the context we provide.
Future simulations could build in a more detailed and accurate description of local voter characteristics, such as household income. They could be tested on a broader set of models, with varying temperatures, and customised/varied context. Future simulations could enable personas to talk to each other, with members of the same household discussing how they would vote. Ideally, simulations would be run 100 or 1,000 times. They would probably also benefit from more than just an afternoon of design and execution.
The real voters of Makerfield have had their say. Now we find out whether any of our four models, and their 42,000 virtual voters, were close to the mark.
 | A guest post by
|
Five hours after posting this the results were in. GPT 5.4-mini was closest, with a Burnham (Labour) victory and Kenyon (Reform) second, and it nicely captured the ~9k gap between them.
Grok, Gemini and DeepSeek were all off the mark, voting for a Reform landslide. The right wing Restore Britain party came in third but barely featured in the simulation, highlighting a limitation of using LLMs and their knowledge cut-offs: the party was established in February 2026 and this was their first time standing a candidate for Westminster.
This experiment tells us more about the diversity of models themselves than anything to do with ‘predicting’ election results. Run enough simulations enough times and you’ll eventually get an eerily accurate forecast. But the divergence given identical prompts is pretty interesting.
In future, we want to run similar simulations but with frontier models. I did a 1% sample with Claude Haiku and Sonnet, but even these turned out to be too expensive for what is an experimental pilot (running this with Opus 4.8 or GPT 5.5 Pro would require a second mortgage).
Chart of results: https://user.fm/files/v2-9e37ac277d867945372e6ef84e26e4e9/actual_vs_models_chart.png
Press coverage: https://aboutmanchester.co.uk/most-ai-models-predicted-a-reform-win-in-makerfield-the-voters-delivered-a-labour-landslide/